 Gestionando tu proyecto con
Gestionando tu proyecto con 

December 19, 2024
Material de las transparencias


Sobre mí

- Profesor Titular de la Universidad de Granada.
- Investigador en Inteligencia Artificial.
- Enseñando ML varios años usando Python y R.
- Usando técnicas de ML en proyectos con empresas.
![]()
¿Qué hace?
¿Cuál es el problema que intenta resolver?


- Múltiples notebooks y modelos.
- Cuál obtiene cada resultado.
- Reproducibilidad.
¿Qué se necesitaría?
Asociar los resultados a cada modelo/parámetros.
Registrar los modelos ya preparados.
Registrar los datos usados.
Poder ejecutar todo con distintos parámetros y/o datos.

MLFlow integrado en el flujo de trabajo
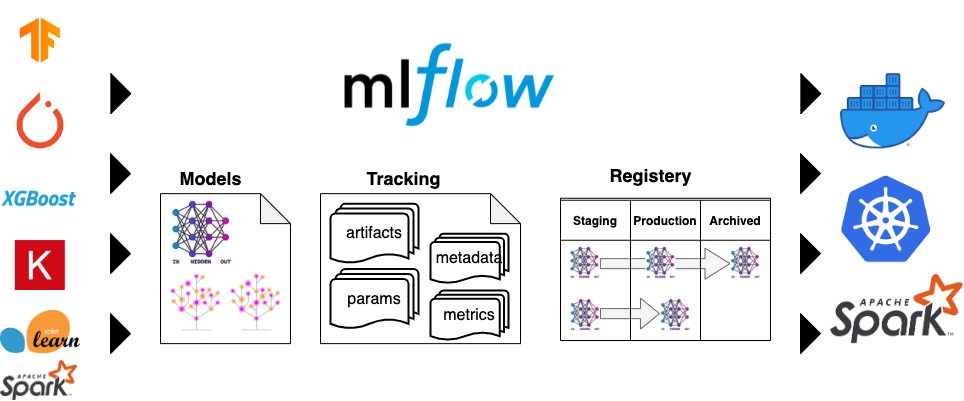
MLFlow conoce las librerías más usadas de ML

Verlo en acción
Primero hay que instalarlo
Lo podemos instalar directamente con pip.
Podemos indicar dónde guardar los datos:
y luego ejecutarlo con:
$ mlflow server mlflow server --backend-store-uri sqlite:///datos.db
...[INFO] Starting gunicorn 23.0.0
...[INFO] Listening at: http://127.0.0.1:5000 (77581)
...[INFO] Using worker: sync
...[INFO] Booting worker with pid: 77582
...[INFO] Booting worker with pid: 77583
...[INFO] Booting worker with pid: 77584
...[INFO] Booting worker with pid: 77585Acceso a MLFlow
Podemos acceder, pero todavía no hay nada interesante.
Primeros ejemplos
Partimos de un código sencillo:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
def main():
iris = load_iris()
# Testing different maximum-depth values
for max_depth in range(1, 6):
# Create a decision tree classifier
clf = DecisionTreeClassifier(max_depth=max_depth)
# Perform cross-validation with 5 folds
scores = cross_val_score(clf, iris.data, iris.target, cv=5).mean()
# Print the cross-validation scores
print(f"Cross-validation scores for max_depth={max_depth}: {scores:.5f}")
main()Cross-validation scores for max_depth=1: 0.66667
Cross-validation scores for max_depth=2: 0.93333
Cross-validation scores for max_depth=3: 0.97333
Cross-validation scores for max_depth=4: 0.95333
Cross-validation scores for max_depth=5: 0.95333Registrando el experimento
Vamos a incorporar el uso de MLFlow inicialmente. Eso implica:
- Indicar dónde se guardarán los datos.
- Crear un experimento asignándole un nombre:
- Delimitar el código asociado a cada ejecución
Para evitar nombres de ejecución aleatorios, le pondremos nombre a cada.
- Guardar los parámetros:
- Guardar los resultados:
Probando el ejemplo completo
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
import mlflow
def main():
iris = load_iris()
mlflow.set_tracking_uri("http://127.0.0.1:5000")
mlflow.set_experiment("Iris - max_depth study")
for max_depth in range(1, 5):
with mlflow.start_run():
mlflow.log_param("max_depth", max_depth)
clf = DecisionTreeClassifier(max_depth=max_depth)
scores = cross_val_score(clf, iris.data, iris.target, cv=5).mean()
print(f"Cross-validation scores for max_depth={max_depth}: {scores:.5f}")
# Registro la métrica
mlflow.log_metric("accuracy", scores)
main()Cross-validation scores for max_depth=1: 0.66667
🏃 View run masked-kite-293 at: http://127.0.0.1:5000/#/experiments/1/runs/26749a7a8057467f90f9ea005ea3608f
🧪 View experiment at: http://127.0.0.1:5000/#/experiments/1
Cross-validation scores for max_depth=2: 0.93333
🏃 View run bedecked-bug-846 at: http://127.0.0.1:5000/#/experiments/1/runs/186d5c271ac74f5a95a8ff82ee67bf67
🧪 View experiment at: http://127.0.0.1:5000/#/experiments/1
Cross-validation scores for max_depth=3: 0.97333
🏃 View run glamorous-shrike-639 at: http://127.0.0.1:5000/#/experiments/1/runs/457c42f5353144c599cec30c4b73bcbe
🧪 View experiment at: http://127.0.0.1:5000/#/experiments/1
Cross-validation scores for max_depth=4: 0.95333
🏃 View run glamorous-crab-195 at: http://127.0.0.1:5000/#/experiments/1/runs/a8225975f2a248808bcdf4ea81b0348e
🧪 View experiment at: http://127.0.0.1:5000/#/experiments/1Volvemos a la página anterior y cambiamos las columnas


Añadiendo más métricas
Permite gestionar muchas métricas a la vez:
Mejoras:
- Guardar la información del modelo:
mlflow.sklearn.log_model(
sk_model=clf,
artifact_path="decision-tree",
registered_model_name="dc-reg-model",
)- Usemos múltiples métricas.
Todo junto
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score, cross_validate
import mlflow
def main():
cancer = load_breast_cancer()
mlflow.set_tracking_uri("http://127.0.0.1:5000")
mlflow.set_experiment("Cancer - max_depth study")
# Testing different maximum-depth values
for max_depth in range(1, 5):
with mlflow.start_run(run_name=f"max_depth-{max_depth}"):
mlflow.log_param("max_depth", max_depth)
clf = DecisionTreeClassifier(max_depth=max_depth)
scores = cross_validate(
clf,
cancer.data,
cancer.target,
cv=5,
scoring=["accuracy", "f1", "recall", "precision", "roc_auc"],
)
for score in scores:
print(score)
print(scores[score].mean())
# Registro la métrica
mlflow.log_metric(score, scores[score].mean())
# Log the sklearn model and register as version 1
mlflow.sklearn.log_model(
sk_model=clf,
artifact_path="decision-tree",
registered_model_name="dc-reg-model",
)
main()fit_time
0.001721668243408203
score_time
0.004060220718383789
test_accuracy
0.8998447446048751
test_f1
0.9228482006526857
test_recall
0.9523082942097026
test_precision
0.8980950168737266
test_roc_auc
0.8821895845356377🏃 View run max_depth-1 at: http://127.0.0.1:5000/#/experiments/2/runs/da1a9f79bad1498ea6efc00ae8b86e5b
🧪 View experiment at: http://127.0.0.1:5000/#/experiments/2
fit_time
0.003262901306152344
score_time
0.004236936569213867
test_accuracy
0.9279614966620089
test_f1
0.9429452065391841
test_recall
0.9496087636932706
test_precision
0.9366239478915535
test_roc_auc
0.9290812380744414🏃 View run max_depth-2 at: http://127.0.0.1:5000/#/experiments/2/runs/c5df0a51b26741db8cfea4a7137bdf78
🧪 View experiment at: http://127.0.0.1:5000/#/experiments/2
fit_time
0.004297208786010742
score_time
0.003939485549926758
test_accuracy
0.924375097034622
test_f1
0.9399703901931081
test_recall
0.9494522691705791
test_precision
0.9316492321243215
test_roc_auc
0.9138665216969344🏃 View run max_depth-3 at: http://127.0.0.1:5000/#/experiments/2/runs/dff1d33d8e4f4526b86f4811d8ba4fc3
🧪 View experiment at: http://127.0.0.1:5000/#/experiments/2
fit_time
0.00438079833984375
score_time
0.003650045394897461
test_accuracy
0.915618692749573
test_f1
0.932739266805541
test_recall
0.9354068857589984
test_precision
0.9309994500910147
test_roc_auc
0.9097761959353019🏃 View run max_depth-4 at: http://127.0.0.1:5000/#/experiments/2/runs/d43c1400aea8420194f0705920eef52e
🧪 View experiment at: http://127.0.0.1:5000/#/experiments/2Vamos a ver qué tal va

Es muy pesado, ¿se puede simplificar?
Auto-logging
MLFlow conoce la mayoría de librerías: Scikit-learn, Keras, PyTorch, XGBoost, …
Permite registrar de forma automática.
# Creo el experimento si no existe
mlflow.set_experiment("Cancer - max_depth study auto")
# Activo el autolog
mlflow.autolog()- Registrará cada modelo, con los distintos parámetros.
Ejemplo
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score, cross_validate
import mlflow
def main():
cancer = load_breast_cancer()
# Añadimos dónde se guardarán los datos
mlflow.set_tracking_uri("http://127.0.0.1:5000")
# Creo el experimento si no existe
mlflow.set_experiment("Cancer - max_depth study auto")
mlflow.autolog()
# Testing different maximum-depth values
for max_depth in range(1, 5):
# Con with no es necesario iniciar y cerrar, es más cómodo
with mlflow.start_run(run_name=f"max_depth-{max_depth}"):
# Create a decision tree classifier
clf = DecisionTreeClassifier(max_depth=max_depth)
# Perform cross-validation with 5 folds
scores = cross_validate(
clf,
cancer.data,
cancer.target,
cv=5,
scoring=["accuracy", "f1", "recall", "precision", "roc_auc"],
)
for score in scores:
print(score)
print(scores[score].mean())
main()fit_time
2.4605133056640627
score_time
0.02682771682739258
test_accuracy
0.8998447446048751
test_f1
0.9228482006526857
test_recall
0.9523082942097026
test_precision
0.8980950168737266
test_roc_auc
0.8821895845356377
🏃 View run max_depth-1 at: http://127.0.0.1:5000/#/experiments/3/runs/1d34b420a02a49dd88322edb75628fe6
🧪 View experiment at: http://127.0.0.1:5000/#/experiments/3fit_time
2.369840621948242
score_time
0.021647214889526367
test_accuracy
0.9279614966620089
test_f1
0.9429452065391841
test_recall
0.9496087636932706
test_precision
0.9366239478915535
test_roc_auc
0.9290812380744414
🏃 View run max_depth-2 at: http://127.0.0.1:5000/#/experiments/3/runs/522fea4c02b141029572243f0f7141bf
🧪 View experiment at: http://127.0.0.1:5000/#/experiments/3fit_time
2.609884262084961
score_time
0.02502584457397461
test_accuracy
0.9173575531749728
test_f1
0.9341145343372524
test_recall
0.9381846635367761
test_precision
0.9306529681143589
test_roc_auc
0.9054158174715823
🏃 View run max_depth-3 at: http://127.0.0.1:5000/#/experiments/3/runs/682d60205efb4ad091d13b4bb42bff4f
🧪 View experiment at: http://127.0.0.1:5000/#/experiments/3fit_time
2.4205743312835692
score_time
0.021451139450073244
test_accuracy
0.9226517621487347
test_f1
0.9381185059275822
test_recall
0.9381846635367761
test_precision
0.9390953560816573
test_roc_auc
0.9205612767908052
🏃 View run max_depth-4 at: http://127.0.0.1:5000/#/experiments/3/runs/186b6c1309764e6898c0a104247bf753
🧪 View experiment at: http://127.0.0.1:5000/#/experiments/3Resultado

Comparando
Podemos comparar las distintas salidas

Reusando el modelo
Reusando el modelo
El modelo no solo se puede registrar de cara a comparar diferencias entre ellos.
Si se registra se puede recuperar simplemente con:
Ejemplo de carga de modelo
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score, cross_validate
import mlflow
def main():
cancer = load_breast_cancer()
# Añadimos dónde se guardarán los datos
mlflow.set_tracking_uri("http://127.0.0.1:5000")
model = mlflow.sklearn.load_model(f"models:/dc-reg-model/4")
# Testing different maximum-depth values
for max_depth in range(1, 5):
# Perform cross-validation with 5 folds
scores = cross_validate(
model,
cancer.data,
cancer.target,
cv=5,
scoring=["accuracy", "f1", "recall", "precision", "roc_auc"],
)
for score in scores:
print(score)
print(scores[score].mean())
main()fit_time
0.005486488342285156
score_time
0.004970359802246094
test_accuracy
0.9314236919732961
test_f1
0.9452613630704395
test_recall
0.9494522691705791
test_precision
0.9424839645892277
test_roc_auc
0.9282586236627346
fit_time
0.005462360382080078
score_time
0.004846763610839844
test_accuracy
0.9243906225741343
test_f1
0.939752668241643
test_recall
0.9438575899843507
test_precision
0.9367351425246163
test_roc_auc
0.920475404104212
fit_time
0.005467605590820312
score_time
0.004978036880493164
test_accuracy
0.9279149200434716
test_f1
0.9426697303418206
test_recall
0.9494522691705791
test_precision
0.9375053017158279
test_roc_auc
0.9191316395357504
fit_time
0.005536556243896484
score_time
0.0047954082489013675
test_accuracy
0.9226517621487347
test_f1
0.9381185059275822
test_recall
0.9381846635367761
test_precision
0.9390953560816573
test_roc_auc
0.9205612767908052Hay mucho más
Registrar los datasets (aunque no es lo mejor que ofrece).
Uso de proyectos (dependencias, ejecución de proyecto enteramente en git).
Desplegar en sistemas de despliegue (docker, kubernete, AWS, …).
Otras opciones
Muchas gracias



